J'ai préparé un court script pour montrer ce que je pense devrait être la bonne intuition.
importer des pandas en tant que pd
importer numpy comme np
importer matplotlib.pyplot comme plt
de sklearn import ensemble
depuis sklearn.model_selection import train_test_split
def create_dataset (emplacement, échelle, N):
class_zero = pd.DataFrame ({
'x': np.random.normal (emplacement, échelle, taille = N),
'y': np.random.normal (emplacement, échelle, taille = N),
«C»: [0,0] * N
})
class_one = pd.DataFrame ({
'x': np.random.normal (-location, échelle, taille = N),
'y': np.random.normal (-location, échelle, taille = N),
«C»: [1,0] * N
})
retourne class_one.append (class_zero, ignore_index = True)
Def préditions (valeurs):
X_train, X_test, tgt_train, tgt_test = train_test_split (valeurs [["x", "y"]], valeurs ["C"], test_size = 0,5, random_state = 9)
clf = ensemble.GradientBoostingRegressor ()
clf.fit (X_train, tgt_train)
y_hat = clf.predict (X_test)
retourner y_hat
N = 10 000
échelle = 1,0
emplacements = [0,0, 1,0, 1,5, 2,0]
f, axarr = plt.subplots (2, len (emplacements))
pour i dans la plage (0, len (emplacements)):
imprimer (i)
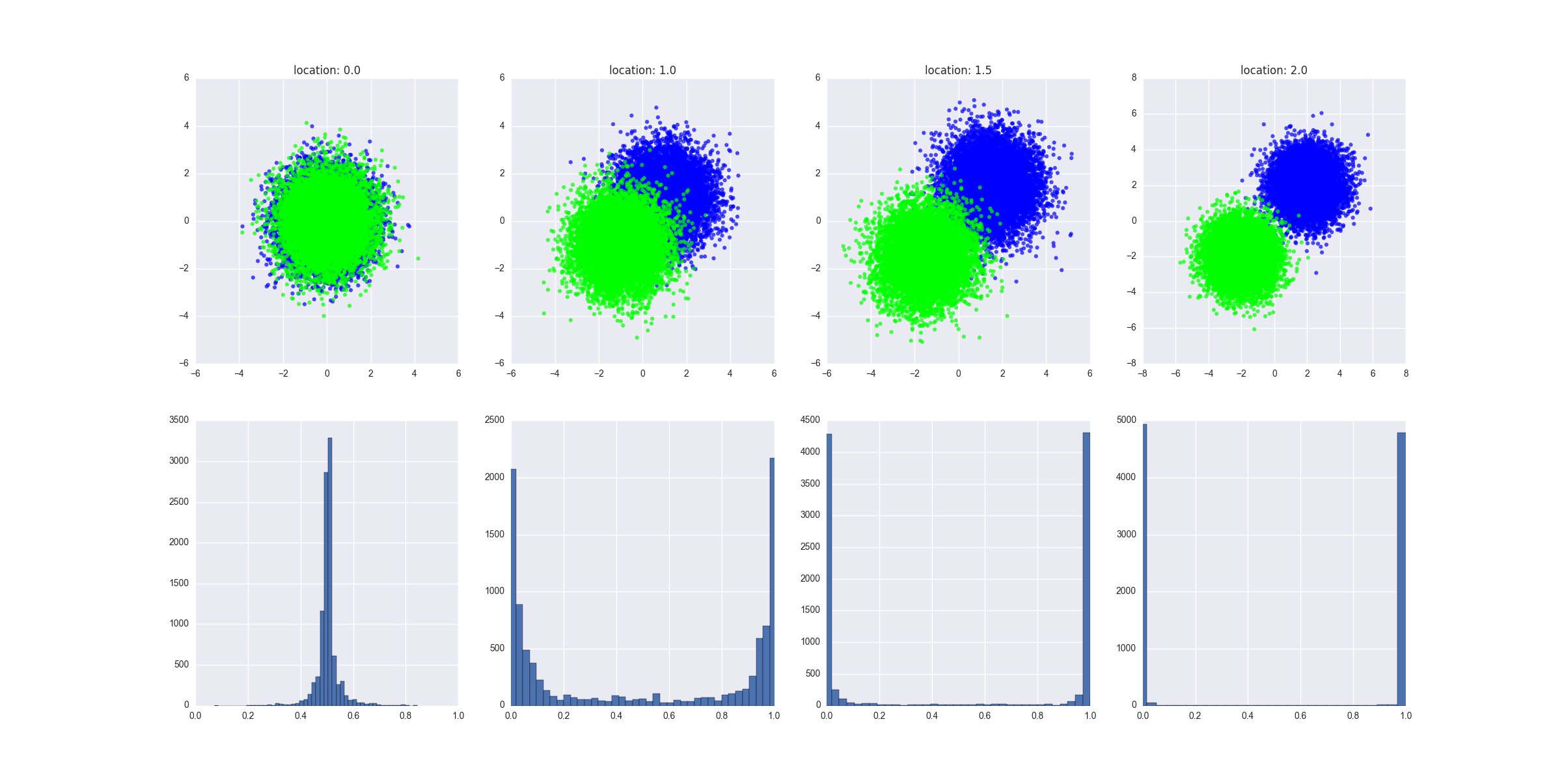
values = create_dataset (emplacements [i], échelle, N)
axarr [0, i] .set_title ("emplacement:" + str (emplacements [i]))
d = valeurs [valeurs C == 0]
axarr [0, i] .scatter (d.x, d.y, c = "# 0000FF", alpha = 0.7, edgecolor = "aucun")
d = valeurs [valeurs C == 1]
axarr [0, i] .scatter (d.x, d.y, c = "# 00FF00", alpha = 0.7, edgecolor = "aucun")
y_hats = préditions (valeurs)
axarr [1, i] .hist (y_hats, bins = 50)
axarr [1, i] .set_xlim ((0, 1))
Ce que fait le script:
- cela crée différents scénarios où les deux classes sont progressivement de plus en plus séparables - je pourrais fournir ici une définition plus formelle de cela mais je suppose que vous devriez avoir l'intuition
- il ajuste un régresseur GBM sur les données de test et génère les valeurs prédites fournissant les valeurs X de test au modèle entraîné
Le graphique produit montre à quoi ressemblent les données générées dans chacun des scénarios et il montre la distribution des valeurs prédites. L'interprétation: le manque de séparabilité se traduit par le fait que $ y $ prédit est égal ou juste autour de 0,5.
Tout cela montre l'intuition, je suppose qu'il ne devrait pas être difficile de le prouver de manière plus formelle, même si je partirais d'une régression logistique - cela rendrait le calcul nettement plus facile.
EDIT 1
Je suppose que dans l'exemple le plus à gauche, où les deux classes ne sont pas
séparable, si vous définissez les paramètres du modèle pour surajuster les données
(par exemple, des arbres profonds, un grand nombre d'arbres et de caractéristiques, relativement
taux d'apprentissage), vous obtiendrez toujours le modèle pour prédire l'extrême
résultats, non? En d'autres termes, la distribution des prédictions est
Indique à quel point le modèle a fini par correspondre aux données?
Supposons que nous ayons un arbre de décision très profond. Dans ce scénario, nous verrions la distribution des valeurs de prédiction culminer à 0 et 1. Nous verrions également une faible erreur d'apprentissage. Nous pouvons rendre l'erreur d'entraînement arbitraire petite, nous pourrions avoir ce surajustement d'arbre profond au point où chaque feuille de l'arbre correspond à un point de données dans l'ensemble de train, et chaque point de données dans l'ensemble de train correspond à une feuille dans l'arbre.
Ce serait la mauvaise performance sur l'ensemble de test d'un modèle très précis sur l'ensemble d'entraînement un signe clair de surajustement. Notez que dans mon graphique, je présente les prédictions sur l'ensemble de test, elles sont beaucoup plus informatives.
Une remarque supplémentaire: travaillons avec l'exemple le plus à gauche. Entraînons le modèle sur tous les points de données de classe A dans la moitié supérieure du cercle et sur tous les points de données de classe B dans la moitié inférieure du cercle. Nous aurions un modèle très précis, avec une distribution des valeurs de prédiction culminant à 0 et 1.
Les prédictions sur l'ensemble de test (tous les points de classe A dans le demi-cercle inférieur et les points de classe B dans le demi-cercle supérieur) culmineraient également à 0 et 1 - mais elles seraient entièrement incorrectes.C'est une mauvaise stratégie de formation «antagoniste».Néanmoins, en résumé: la distribution jette comme sur le degré de séparabilité, mais ce n'est pas vraiment ce qui compte.