Il est inhabituel de ne pas correspondre à une interception et généralement déconseillé - on ne devrait le faire que si vous savez que c'est 0, mais je pense que (et le fait que vous ne pouvez pas comparer le $ R ^ 2 $ pour les ajustements avec et sans interception) est bel et bien déjà couverte (si possible un peu surestimée dans le cas de l'interception 0); Je veux me concentrer sur votre problème principal qui est que vous avez besoin que la fonction ajustée soit positive, bien que je revienne au problème de l'interception 0 dans une partie de ma réponse.
La meilleure façon d'obtenir un toujours l'ajustement positif est d'adapter quelque chose qui sera toujours positif; en partie qui dépend des fonctions que vous devez ajuster.
Si votre modèle linéaire était en grande partie un modèle de commodité (plutôt que de provenir d'une relation fonctionnelle connue qui pourrait provenir d'un modèle physique, par exemple), alors vous pourrait à la place fonctionner avec le log-time; le modèle ajusté est alors garanti positif en $ t $. Comme alternative, vous pouvez travailler avec la vitesse plutôt que le temps - mais avec les ajustements linéaires, vous pouvez avoir un problème avec de petites vitesses (temps longs) à la place.
Si vous savez que votre réponse est linéaire dans les prédicteurs, vous pouvez essayer d'ajuster une régression contrainte, mais avec une régression multiple, la forme exacte dont vous avez besoin dépendra de vos x particuliers (il n'y a pas de contrainte linéaire qui fonctionnera pour tous les $ x $), donc c'est un bit ad-hoc.
Vous pouvez également regarder les GLM qui peuvent être utilisés pour ajuster des modèles qui ont des valeurs ajustées non négatives et peuvent (si nécessaire) même avoir $ E (Y) = X \ beta $ .
Par exemple, on peut adapter un gamma GLM avec un lien d'identité. Vous ne devriez pas vous retrouver avec une valeur ajustée négative pour l'un de vos x (mais vous pourriez peut-être avoir des problèmes de convergence dans certains cas si vous forcez le lien d'identité là où il ne rentre vraiment pas).
Voici un exemple: l'ensemble de données voitures dans R, qui enregistre la vitesse et les distances d'arrêt (la réponse).
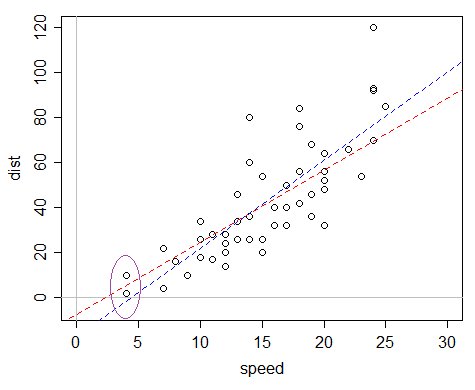
On pourrait dire "oh, mais la distance pour la vitesse 0 est garantie égale à 0, donc nous devrions omettre l'interception" mais le problème avec ce raisonnement est que le modèle est mal spécifié de plusieurs manières, et cet argument ne fonctionne que bien assez quand le modèle n'est pas mal spécifié - un modèle linéaire avec 0 interception ne convient pas du tout dans ce cas, tandis qu'un modèle avec une interception est en fait une approximation à moitié décente même si ce n'est pas réellement "correct".
Le problème est que si vous ajustez une régression linéaire ordinaire, l'intersection ajustée est plutôt négative, ce qui fait que les valeurs ajustées sont négatives.
La ligne bleue est l'ajustement OLS; la valeur ajustée pour les plus petites valeurs x de l'ensemble de données est négative. La ligne rouge est le gamma GLM avec lien d'identité - tout en ayant une interception négative, il n'a que des valeurs ajustées positives. Ce modèle a une variance proportionnelle à la moyenne, donc si vous trouvez que vos données sont plus étalées à mesure que le temps prévu augmente, il peut être particulièrement approprié.
C'est donc une approche alternative possible qui vaut peut-être la peine d'être essayée. C'est presque aussi simple que d'ajuster une régression dans R.
Si vous n'avez pas besoin du lien d'identité, vous pouvez envisager d'autres fonctions de lien, comme le lien log et le lien inverse, qui concernent les transformations déjà discuté, mais sans la nécessité d'une transformation réelle.
Puisque les gens le demandent habituellement, voici le code de mon intrigue:
plot (dist ~ speed, data = cars, xlim = c (0, 30), ylim = c (-5,120)) abline (h = 0, v = 0, col = 8) abline (glm (dist ~ vitesse, données = voitures, famille = Gamma (lien = identité)), col = 2 , lty = 2) abline (lm (dist ~ speed, data = cars), col = 4, lty = 2)
(L'ellipse a été ajoutée à la main par la suite, même si c'est assez facile à faire aussi en R)