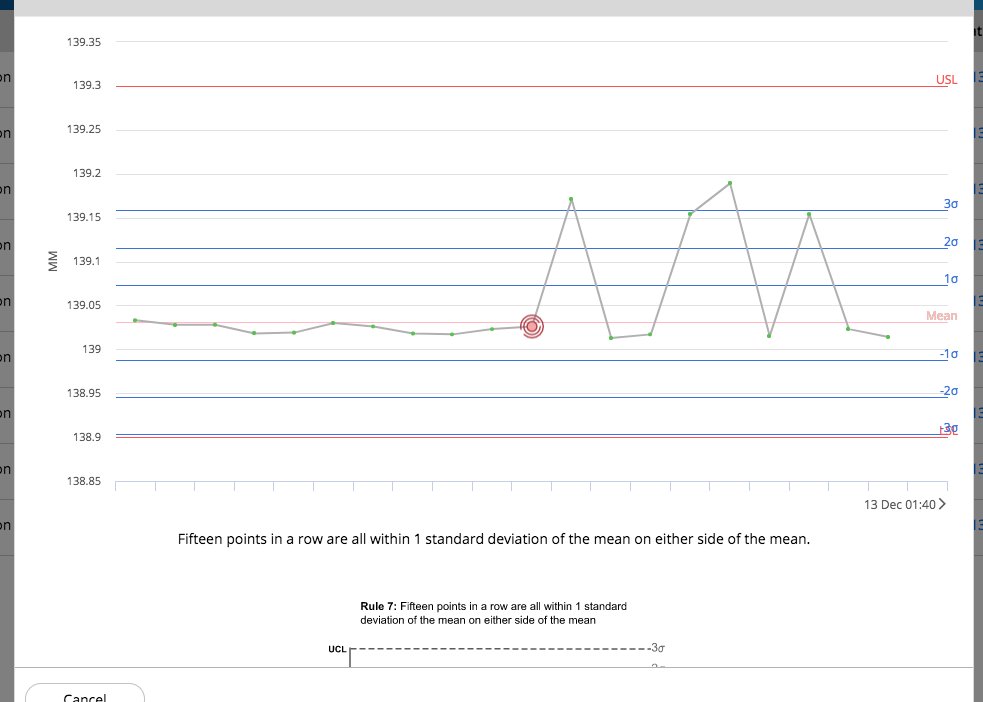
avertissement - cette méthode est ad hoc et sans étude rigoureuse. Utilisez à vos risques et périls :)
Ce que j'ai trouvé assez bon, c'est de réduire la pertinence d'une contribution en points à la moyenne par l'square de son nombre d'écarts-types par rapport à la moyenne mais seulement si le point est plus d'un écart-type de la moyenne.
Étapes:
- Calculez la moyenne et l'écart type comme d'habitude.
- Recalculez la moyenne, mais cette fois, pour chaque valeur, si elle est plus d'un écart-type de la moyenne réduit sa contribution à la moyenne. Pour réduire sa contribution, divisez sa valeur par le carré de son nombre d'écarts avant d'ajouter au total. De plus, parce qu'il contribue moins, nous devons réduire N, donc soustraire 1-1 / (carré de l'écart des valeurs) de N.
- Recalculez l'écart type, mais utilisez cette nouvelle moyenne plutôt que l'ancienne.
exemple:
stddev = 0,5
moyenne = 10
valeur = 11
alors, écarts = distance de la moyenne / stddev = | 10-11 | /0.5 = 2
donc la valeur passe de 11 à 11 / (2) ^ 2 = 11/4
également N change, il est réduit à N-3/4.
code:
par défaut moyenne (données):
"" "Renvoie l'exemple de moyenne arithmétique des données." ""
n = len (données)
si n < 1:
lever ValueError ('mean requiert au moins un point de données')
return 1.0 * sum (data) / n # en Python 2 utiliser sum (data) / float (n)
def _ss (données):
"" "Renvoie la somme des écarts carrés des données de séquence." ""
c = moyenne (données)
ss = somme ((x-c) ** 2 pour x dans les données)
retour ss, c
def stddev (données, ddof = 0):
"" "Calcule l'écart type de la population
par défaut; spécifiez ddof = 1 pour calculer l'échantillon
écart-type."""
n = len (données)
si n < 2:
lever ValueError ('la variance nécessite au moins deux points de données')
ss, c = _ss (données)
pvar = ss / (n-ddof)
retourne pvar ** 0,5, c
def rob_adjusted_mean (valeurs, s, m):
n = 0,0
tot = 0,0
pour v en valeurs:
diff = abs (v - m)
écarts = diff / s
si écarts > 1:
# c'est une valeur aberrante, alors réduisez sa pertinence / pondération par carré de son nombre d'écarts
n + = 1,0 / écarts ** 2
tot + = v / écarts ** 2
autre:
n + = 1
tot + = v
retour tot / n
def rob_adjusted_ss (valeurs, s, m):
"" "Renvoie la somme des écarts carrés des données de séquence." ""
c = rob_adjusted_mean (valeurs, s, m)
ss = somme ((x-c) ** 2 pour x en valeurs)
retour ss, c
def rob_adjusted_stddev (données, s, m, ddof = 0):
"" "Calcule l'écart type de la population
par défaut; spécifiez ddof = 1 pour calculer l'échantillon
écart-type."""
n = len (données)
si n < 2:
lever ValueError ('la variance nécessite au moins deux points de données')
ss, c = rob_adjusted_ss (données, s, m)
pvar = ss / (n-ddof)
retourne pvar ** 0,5, c
s, m = stddev (valeurs, ddof = 1)
imprimer s, m
s, m = rob_adjusted_stddev (valeurs, s, m, ddof = 1)
imprimer s, m
sortie avant et après ajustement de mes 50 mesures:
0.0409789841609 139.04222
0,0425867309757 139,030745443