D'accord, donc celui-ci est moins une illustration d'un concept de base, mais il est très intéressant à la fois visuellement et en termes d'applications. Je pense que montrer aux gens ce qu'ils peuvent finalement accomplir avec ce qu'ils apprennent est une excellente forme de motivation, vous pouvez donc le présenter comme un exemple de développement et d'application de modèles statistiques, qui dépend de tous les concepts statistiques plus fondamentaux qu'ils apprennent. Sur ce, je vous présente ...
Species Distribution Modelling
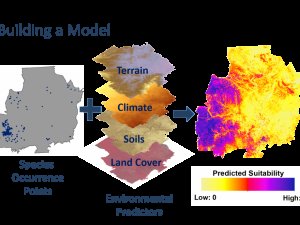
C'est en fait un sujet très large avec beaucoup de nuances en termes de types de données, de collecte de données, de configuration de modèle, d'hypothèses, d'applications, d'interprétations, etc. Mais en termes simples, vous prenez des exemples d'informations sur l'emplacement d'une espèce, puis utiliser ces emplacements pour échantillonner des variables environnementales potentiellement pertinentes (par exemple, données climatiques, données sur le sol, données sur l'habitat, altitude, pollution lumineuse, pollution sonore, etc.), développer un modèle en utilisant les données (par exemple, GLM, modèle de processus ponctuel, etc.) , puis utilisez ce modèle pour prédire dans un paysage à l'aide de vos variables environnementales. En fonction de la configuration du modèle, ce qui est prédit peut être un habitat convenable potentiel, des zones d'occurrence probables, la distribution des espèces, etc. Vous pouvez également modifier les variables environnementales pour voir comment elles affectent ces résultats. Les gens ont utilisé des MDS pour trouver des populations auparavant inconnues d'une espèce, ils les ont utilisés pour découvrir de nouvelles espèces, avec des données climatiques historiques, ils les ont utilisées pour prédire à rebours dans le temps où une espèce se trouvait et comment elle est arrivée là où elle est aujourd'hui (même tout au long des périodes de glaciation), et avec des choses comme les prévisions climatiques futures et la perte d'habitat, elles sont utilisées pour prédire comment les activités humaines affecteront l'espèce à l'avenir. Ce ne sont là que quelques exemples, et si j'ai le temps plus tard, je trouverai et relierai des articles intéressants. En attendant, voici une petite image que j'ai trouvée illustrant les bases: