J'ai trouvé la réponse de BruceET intéressante, relative au nombre d'événements. Une autre manière d'aborder ce problème est d'utiliser la correspondance entre le temps d'attente et le nombre d'événements. L'utilisation de cela serait que le problème pourra être généralisé d'une certaine manière plus facilement.
Affichage du problème comme un problème de temps d'attente
Cette correspondance, comme par exemple expliqué / utilisé ici et ici, est
Pour le nombre de lancers de dés $ m $ et le nombre de coups / événements $ k $ vous avoir:
$$ \ begin {array} {ccc}
\ overbrace {P (K \ geq k | m)} ^ {\ text {c'est ce que vous cherchez}} & = &
\ overbrace {P (M \ leq m | k)} ^ {\ text {nous allons l'exprimer à la place}} \\
{\ small \ text {$ \ mathbb {P} $ $ k $ ou plus d'événements dans $ m $ lancers de dés}} & = & {\ small \ text {$ \ mathbb {P} $ jetons de dés en dessous de $ m $ donné $ k $ événements}}
\ end {tableau}
$$
En mots: la probabilité d'obtenir plus de $ K \ geq k $ événements (par exemple $ \ geq 1 $ fois 6) dans un certain nombre de lancers de dés $ m $ est égal à la probabilité d'avoir besoin de $ m $ ou moins de dés pour obtenir $ k $ de tels événements.
Cette approche concerne de nombreuses distributions.
Distribution de la distribution de
Temps d'attente entre les événements nombre d'événements
Poisson exponentiel
Erlang / Gamma sur / sous-dispersé Poisson
Binôme géométrique
Binomial négatif sur / sous-dispersé Binomial
Donc, dans notre situation, le temps d'attente est une distribution géométrique. La probabilité que le nombre de dés lancés $ M $ avant de lancer le premier $ n $ soit inférieure à ou égal à $ m $ (et étant donné une probabilité de rouler $ n $ est égal à $ 1 / n $ ) est le CDF suivant pour la distribution géométrique:
$$ P (M \ leq m) = 1- \ left (1- \ frac {1} {n} \ right) ^ m $$
et nous recherchons la situation $ m = n $ donc vous obtenez:
$$ P (\ text {il y aura un $ n $ roulé dans $ n $ rolls}) = P (M \ leq n) = 1- \ left (1 - \ frac {1} {n} \ right) ^ n $$
Généralisations, lorsque $ n \ to \ infty $
La première généralisation est que pour $ n \ to \ infty $ la distribution du nombre d'événements devient Poisson avec le facteur $ \ lambda $ et le temps d'attente devient une distribution exponentielle avec le facteur $ \ lambda $ . Ainsi, le temps d'attente pour lancer un événement dans le processus de lancement des dés de Poisson devient $ (1-e ^ {- \ lambda \ times t}) $ et avec $ t = 1 $ nous obtenons le même résultat $ \ environ 0,632 $ que les autres réponses. Cette généralisation n'est pas encore si particulière car elle ne reproduit que les autres résultats, mais pour le suivant je ne vois pas aussi directement comment la généralisation pourrait fonctionner sans penser aux temps d'attente.
Généralisations, quand les dés ne sont pas justes
Vous pourriez envisager la situation où les dés ne sont pas justes. Par exemple, une fois, vous lancerez un dé avec une probabilité de 0,17 de lancer un 6, et une autre fois, vous lancerez un dé avec une probabilité de 0,16 de lancer un 6. Cela signifiera que les 6 seront plus regroupés autour des dés avec un biais positif. , et que la probabilité de lancer un 6 en 6 tours sera inférieure au chiffre 1-1 $ / e $ . (cela signifie que sur la base de la probabilité moyenne d'un seul jet, disons que vous l'avez déterminée à partir d'un échantillon de plusieurs lancers, vous ne pouvez pas déterminer la probabilité dans de nombreux lancers avec les mêmes dés, car vous devez prendre en compte la corrélation du dés)
Disons qu'un dé n'a pas de probabilité constante $ p = 1 / n $ , mais à la place il est tiré d'une distribution bêta avec une moyenne $ \ bar {p} = 1 / n $ et un paramètre de forme $ \ nu $
$$ p \ sim Beta \ left (\ alpha = \ nu \ frac {1} {n}, \ beta = \ nu \ frac {n-1} {n } \ droite) $$
Ensuite, le nombre d'événements pour un dé particulier lancé $ n $ time sera binomial bêta distribué. Et la probabilité pour 1 ou plusieurs événements sera:
$$ P (k \ geq 1) = 1 - \ frac {B (\ alpha, n + \ beta)} {B (\ alpha, \ beta)} = 1 - \ frac {B (\ nu \ frac {1} {n}, n + \ nu \ frac {n-1} {n})} {B (\ nu \ frac {1} {n}, n + \ nu \ frac {n-1} {n})} $$
Je peux vérifier par ordinateur que cela fonctionne ...
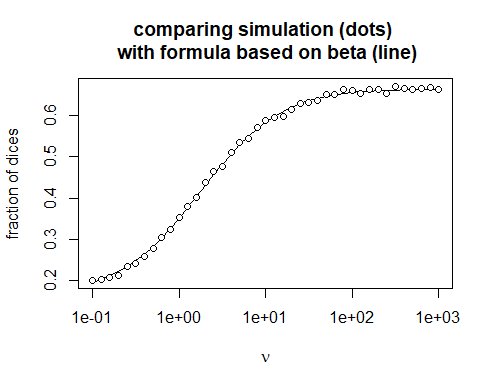
### calculer le résultat pour lancer un dé à n faces n fois
rolldice <- fonction (n, nu) {
p <- rbeta (1, nu * 1 / n, nu * (n-1) / n)
k <- rbinom (1, n, p)
sur <- (k>0)
en dehors
}
### calculer la moyenne d'un échantillon de dés
meandice <- fonction (n, nu, reps = 10 ^ 4) {
somme (répliquer (reps, rolldice (n, nu))) / reps
}
meandice <- Vectoriser ((meandice))
### simuler et calculer la variance n
set.seed (1)
n <- 6
nu <- 10 ^ seq (-1,3,0.1)
y <- meandice (n, nu)
plot (nu, 1-beta (nu * 1 / n, n + nu * (n-1) / n) / beta (nu * 1 / n, nu * (n-1) / n), log = "x ", xlab = expression (nu), ylab =" fraction de dés ",
main = "comparaison de la simulation (points) \ n avec une formule basée sur bêta (ligne)", main.cex = 1, type = "l")
points (nu, y, lty = 1, pch = 21, col = "noir", bg = "blanc")
.... Mais je n'ai aucun bon moyen de résoudre analytiquement l'expression pour $ n \ to \ infty $ .
Wavec le temps d'attente Cependant, avec les temps d'attente, je peux alors exprimer la limite de la distribution binomiale bêta (qui ressemble maintenant plus à une distribution bêta de Poisson) avec une variance du facteur exponentiel des temps d'attente.
Donc, au lieu de $ 1-e ^ {- 1} $ , nous recherchons $$ 1- \ int e ^ {- \ lambda} p (\ lambda) \, \ text {d} \, \ lambda $$ .
Maintenant, ce terme intégral est lié à la fonction génératrice de moment (avec $ t = -1 $ ). Donc, si $ \ lambda $ est distribué normalement avec $ \ mu = 1 $ et la variance $ \ sigma ^ 2 $ alors nous devrions utiliser:
$$ 1-e ^ {- (1- \ sigma ^ 2/2)} \ quad \ text {au lieu de} \ quad 1-e ^ {- 1} $$
Application
Ces lancers de dés sont un modèle de jouet. De nombreux problèmes de la vie réelle auront des variations et des situations de dés pas tout à fait équitables.
Par exemple, supposons que vous souhaitiez étudier la probabilité qu'une personne soit malade à cause d'un virus avec un certain temps de contact. On pourrait baser les calculs pour cela sur la base de certaines expériences qui vérifient la probabilité d'une transmission (par exemple, soit des travaux théoriques, soit des expériences de laboratoire mesurant / déterminant le nombre / la fréquence des transmissions dans une population entière sur une courte durée), puis extrapoler cette transmission à un mois entier. Supposons que vous constatiez que la transmission correspond à 1 transmission par mois et par personne, alors vous pourriez conclure que 1-1 $ / e \ environ 0,63 \% $ de la population recevra malade. Cependant, cela pourrait être une surestimation car tout le monde ne pourrait pas tomber malade / transmettre avec le même taux. Le pourcentage diminuera probablement.
Cependant, cela n'est vrai que si la variance est très grande. Pour cela, la distribution de $ \ lambda $ doit être très biaisée. Parce que, bien que nous l'ayons exprimé comme une distribution normale auparavant, les valeurs négatives ne sont pas possibles et les distributions sans distributions négatives n'auront généralement pas de grands ratios $ \ sigma / \ mu $ , sauf s'ils sont fortement biaisés. Une situation avec une inclinaison élevée est modélisée ci-dessous:
Nous utilisons maintenant le MGF pour une distribution de Bernoulli (l'exposant de celle-ci), car nous avons modélisé la distribution comme suit: $ \ lambda = 0 $ avec probabilité $ 1-p $ ou $ \ lambda = 1 / p $ avec probabilité $ p $ .
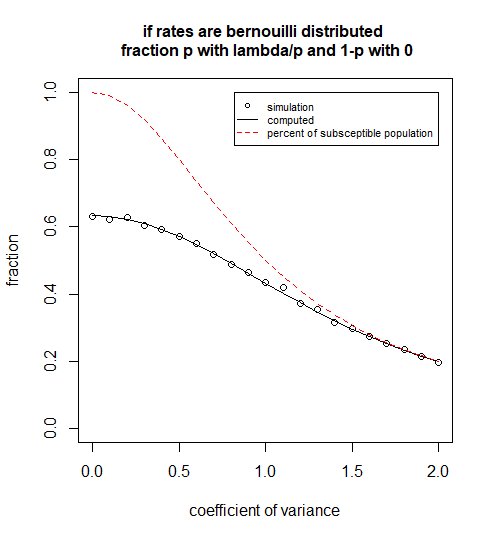
set.seed (1)
taux = 1
temps = 1
CV = 1
### calculer le résultat de la maladie avec un taux variable
getsick <- fonction (taux, CV = 0,1, temps = 1) {
### tronquer les changements sd et mean mais pas beaucoup si CV est petit
p <- 1 / (CV ^ 2 + 1)
lambda <- rbinom (1,1, p) / (p) * taux
k <- rpois (1, lambda * heure)
sur <- (k>0)
en dehors
}
CV <- seq (0,2,0,1)
plot (-1, -1, xlim = c (0,2), ylim = c (0,1), xlab = "coefficient de variance", ylab = "fraction",
cex.main = 1, main = "si les taux sont distribués en bernouilli \ n fraction p avec lambda / p et 1-p avec 0")
for (cv dans CV) {
points (cv, somme (répliquer (10 ^ 4, getsick (rate = 1, cv, time = 1))) / 10 ^ 4)
}
p <- 1 / (CV ^ 2 + 1)
lignes (CV, 1- (1-p) -p * exp (-1 / p), col = 1)
lignes (CV, p, col = 2, lty = 2)
légende (2,1, c ("simulation", "calculé", "pourcentage de la population subsceptible"),
col = c (1,1,2), lty = c (NA, 1,2), pch = c (1, NA, NA), xjust = 1, cex = 0,7)
La conséquence est. Supposons que vous ayez un $ n $ élevé et que vous n’ayez aucune possibilité d’observer des lancers de dés $ n $ (par exemple, il faut à long), et à la place vous filtrez le nombre de $ n $ lancers seulement pendant une courte période pour de nombreux dés différents. Ensuite, vous pouvez calculer le nombre de dés qui ont lancé un nombre $ n $ pendant ce court laps de temps et en vous basant sur ce calcul, ce qui se passerait pour $ n $ rouleaux. Mais vous ne sauriez pas à quel point les événements sont corrélés dans les dés. Il se peut que vous ayez affaire à une probabilité élevée dans un petit groupe de dés, au lieu d'une probabilité uniformément répartie entre tous les dés.
Cette «erreur» (ou vous pourriez dire simplification) se rapporte à la situation avec le COVID-19 où l'idée circule que nous avons besoin de 60% des personnes immunisées pour atteindre l'immunité collective. Cependant, ce n'est peut-être pas le cas. Le taux d'infection actuel n'est déterminé que pour un petit groupe de personnes, il se peut qu'il ne s'agisse que d'une indication de la contagiosité d'un petit groupe de personnes.